


© janaka dharmasena dreamstime.com_technical
Technologie |
Test wydajności GAP8 i ARM M7 dla wbudowanych splotowych sieci neuronowych (CNN)
W systemach IoT wzrasta popularność wykorzystania splotowych sieci neuronowych do analizy danych bezpośrednio u źródła.
Połączone urządzenia, czyli internet rzeczy (IoT), w ciągu ostatnich kilku lat szybko się rozpowszechniły i według ostatnich prognoz do roku 2035 pojawi się jeszcze trylion takich urządzeń w różnych segmentach rynku. Wykorzystywane dzisiaj urządzenia IoT składają się zazwyczaj z czujników zbierających dane, takich jak: dźwięk, obraz, temperatura, wilgotność, lokalizacja GPS i przyspieszenie. Następnie są one przetwarzane przez narzędzia analityczne w chmurze, tak aby umożliwić wykorzystanie szerokiego zakresu aplikacji i przesyłane do innych węzłów lub do chmury.
 Rysunek 1. Porównanie wielkości procesora GAP8 do jednego eurocenta, © ARM
Nowy układ to wysoce oszczędny w pobór energii System-on-a-Chip, umożliwiający masowe wdrażanie tanich i inteligentnych urządzeń, które przechwytują, analizują, klasyfikują i działają na połączeniu różnych źródeł danych, takich jak obrazy, dźwięki lub wibracje. GAP8 łączy w sobie wszystko, co niezbędne do obsługi czujników: wstępne przetwarzanie, analizę i wydajną pracę na rozbudowanych źródłach danych. Posiada 8 rdzeni oraz akcelerator HWCE (Hardware Convolution Engine). Dzięki temu GAP8 posiada wysoką wydajność energetyczną, która umożliwia działanie urządzeń IoT na akumulatorach przez wiele lat, zapewniając tym samym niskie koszty instalacji i eksploatacji. Nowy procesor kieruje się do produktów przemysłowych i konsumenckich integrujących sztuczną inteligencję i zaawansowane funkcje, takie jak rozpoznawanie obrazu, liczenie ludzi i przedmiotów, monitorowanie stanu maszyn, ochrona domów i mieszkań, rozpoznawanie mowy, robotyka konsumencka, urządzenia do noszenia i inteligentne zabawki.
Rysunek 1. Porównanie wielkości procesora GAP8 do jednego eurocenta, © ARM
Nowy układ to wysoce oszczędny w pobór energii System-on-a-Chip, umożliwiający masowe wdrażanie tanich i inteligentnych urządzeń, które przechwytują, analizują, klasyfikują i działają na połączeniu różnych źródeł danych, takich jak obrazy, dźwięki lub wibracje. GAP8 łączy w sobie wszystko, co niezbędne do obsługi czujników: wstępne przetwarzanie, analizę i wydajną pracę na rozbudowanych źródłach danych. Posiada 8 rdzeni oraz akcelerator HWCE (Hardware Convolution Engine). Dzięki temu GAP8 posiada wysoką wydajność energetyczną, która umożliwia działanie urządzeń IoT na akumulatorach przez wiele lat, zapewniając tym samym niskie koszty instalacji i eksploatacji. Nowy procesor kieruje się do produktów przemysłowych i konsumenckich integrujących sztuczną inteligencję i zaawansowane funkcje, takie jak rozpoznawanie obrazu, liczenie ludzi i przedmiotów, monitorowanie stanu maszyn, ochrona domów i mieszkań, rozpoznawanie mowy, robotyka konsumencka, urządzenia do noszenia i inteligentne zabawki.
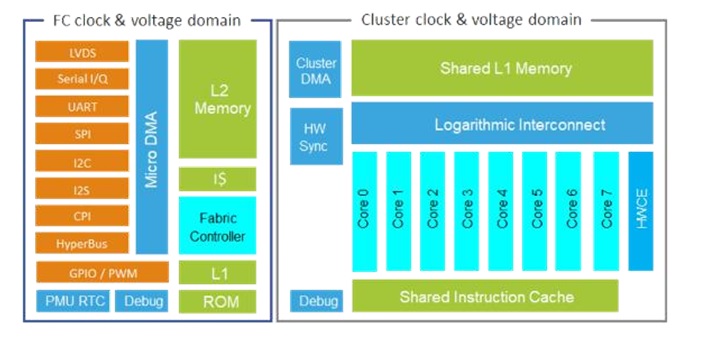 Rysunek 2. Schemat blokowy mikroprocesora GAP8
Testom porównawczym wydajności obliczeniowej poddano dwa mikrokontrolery GAP8 i STM32 F7 oparty na rdzeniu ARM Cortex-M7. W obu przypadkach wykorzystano ten sam graf sieci neuronowej wyszkolonej w zestawie danych CIFAR-10, składający się z 60 000 kolorowych obrazów 32x32 podzielonych na 10 klas. Firma ARM w swoich testach wykorzystała również mikrokontroler STM32 F7. Układ F7 produkowany jest w technologii 90 nm, która jest szczególnie mało energooszczędna, kiedy wykorzystujemy w testach maksymalną prędkość 217 MHz. Dla uzyskania większej wiarygodności rezultatów w testach poboru mocy wykorzystano układ STM32 H7, który posiada maksymalną częstotliwość taktowania równą 400 MHz. Wykorzystując z tego jedynie 217 MHz zagwarantowano dużo mniejsze zużycie energii i porównywalność wyników. STM32 H7 bazuje na tym samym rdzeniu co ARM M7, co gwarantuje podobny cykl pracy jak w F7. Dodatkowo układ wytwarzany jest w technologii 40 nm, która jest dużo bardziej bliższa technologii 55-nanometrowego procesu TSMC zastosowanego w układzie GAP8.
Rysunek 2. Schemat blokowy mikroprocesora GAP8
Testom porównawczym wydajności obliczeniowej poddano dwa mikrokontrolery GAP8 i STM32 F7 oparty na rdzeniu ARM Cortex-M7. W obu przypadkach wykorzystano ten sam graf sieci neuronowej wyszkolonej w zestawie danych CIFAR-10, składający się z 60 000 kolorowych obrazów 32x32 podzielonych na 10 klas. Firma ARM w swoich testach wykorzystała również mikrokontroler STM32 F7. Układ F7 produkowany jest w technologii 90 nm, która jest szczególnie mało energooszczędna, kiedy wykorzystujemy w testach maksymalną prędkość 217 MHz. Dla uzyskania większej wiarygodności rezultatów w testach poboru mocy wykorzystano układ STM32 H7, który posiada maksymalną częstotliwość taktowania równą 400 MHz. Wykorzystując z tego jedynie 217 MHz zagwarantowano dużo mniejsze zużycie energii i porównywalność wyników. STM32 H7 bazuje na tym samym rdzeniu co ARM M7, co gwarantuje podobny cykl pracy jak w F7. Dodatkowo układ wytwarzany jest w technologii 40 nm, która jest dużo bardziej bliższa technologii 55-nanometrowego procesu TSMC zastosowanego w układzie GAP8.
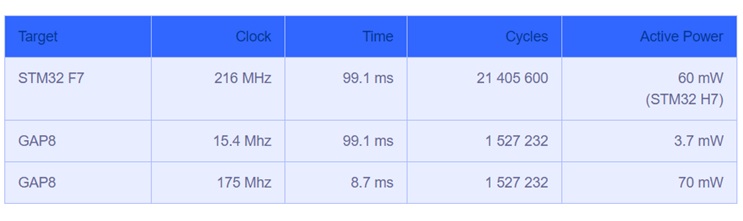 Tabela 1. Wyniki testów porównawczych wydajności obliczeniowej dla GAP8 i STM32 F7 oraz poboru mocy dla GAP8 i STM32 H7
Analiza testów wydajności
W przypadku układu STM32 F7 prędkość wnioskowania wyniosła 99,1 ms przy wykonanych 21 milionach cykli (wszystkie wagi posiadały 8-bitową kwantyzację sygnału). Natomiast w specyfikacji producent deklaruje wydajność na poziomie 24.7 MOPS. Osiągnięty rezultat może świadczyć o tym, że jest jeszcze miejsce na dalszą optymalizację architektury ARM. GAP8 wymaga jedynie 1,5 miliona cykli do uruchomienia tej samej operacji. Dlaczego GAP8 wykorzystuje tak mało cykli? Po pierwsze, pracuje na 8 rdzeniach, a niezwykle wydajna architektura stworzona do zapewnienia równoległości procesów, umożliwia uzyskanie od 7 do 8-krotnego współczynnika przyspieszenia (speedup). Po drugie, zoptymalizowane instrukcje DSP/SIMD w GAP8 zapewniają wysoką równoległość operacjom splotu. I wreszcie precyzyjna kontrola pamięci generuje prawdziwą korzyść w postaci liczby cykli używanych do ładowania i przechowywania wag oraz danych wejściowych i wyjściowych z węzłów grafów sieci neuronowej. Wszystkie wspomniane czynniki pozwalają osiągnąć ten sam czas wykonania wnioskowania 99,1 ms, jednak dla dużo mniejszej prędkości zegara 15,4 MHz. To z kolei pozwala na uruchamianie rdzeni już przy napięciu 1V i redukcję zużycia energii do poziomu 3,7 mW podczas pracy. Uzyskana w teście wydajność energetyczna układu GAP8 jest 16-krotnie lepsza w stosunku do rdzenia M7 zaimplementowanego w STM32 H7. Jest to więc dobry powód do tego, żeby dla podobnych obciążeń wybrać bardziej energooszczędny układ GAP8.
Dla porównania wykonano test dla maksymalnej prędkości zegara w GAP8 - 175 MHz i napięcia 1,2V. Uzyskano 11-krotny wzrost wydajności obliczeniowej w porównaniu do rdzenia M7. Większa prędkość wnioskowania – 8,7 ms – została osiągnięta kosztem większego zużycia energii – 70mW. Zużyta energia jest oczywiście mniejsza niż dla M7, ponieważ cykl trwa krócej, ale z punktu widzenia zużycia energii układ GAP8 okazał się mniej wydajny w tym punkcie pracy.
Tabela 1. Wyniki testów porównawczych wydajności obliczeniowej dla GAP8 i STM32 F7 oraz poboru mocy dla GAP8 i STM32 H7
Analiza testów wydajności
W przypadku układu STM32 F7 prędkość wnioskowania wyniosła 99,1 ms przy wykonanych 21 milionach cykli (wszystkie wagi posiadały 8-bitową kwantyzację sygnału). Natomiast w specyfikacji producent deklaruje wydajność na poziomie 24.7 MOPS. Osiągnięty rezultat może świadczyć o tym, że jest jeszcze miejsce na dalszą optymalizację architektury ARM. GAP8 wymaga jedynie 1,5 miliona cykli do uruchomienia tej samej operacji. Dlaczego GAP8 wykorzystuje tak mało cykli? Po pierwsze, pracuje na 8 rdzeniach, a niezwykle wydajna architektura stworzona do zapewnienia równoległości procesów, umożliwia uzyskanie od 7 do 8-krotnego współczynnika przyspieszenia (speedup). Po drugie, zoptymalizowane instrukcje DSP/SIMD w GAP8 zapewniają wysoką równoległość operacjom splotu. I wreszcie precyzyjna kontrola pamięci generuje prawdziwą korzyść w postaci liczby cykli używanych do ładowania i przechowywania wag oraz danych wejściowych i wyjściowych z węzłów grafów sieci neuronowej. Wszystkie wspomniane czynniki pozwalają osiągnąć ten sam czas wykonania wnioskowania 99,1 ms, jednak dla dużo mniejszej prędkości zegara 15,4 MHz. To z kolei pozwala na uruchamianie rdzeni już przy napięciu 1V i redukcję zużycia energii do poziomu 3,7 mW podczas pracy. Uzyskana w teście wydajność energetyczna układu GAP8 jest 16-krotnie lepsza w stosunku do rdzenia M7 zaimplementowanego w STM32 H7. Jest to więc dobry powód do tego, żeby dla podobnych obciążeń wybrać bardziej energooszczędny układ GAP8.
Dla porównania wykonano test dla maksymalnej prędkości zegara w GAP8 - 175 MHz i napięcia 1,2V. Uzyskano 11-krotny wzrost wydajności obliczeniowej w porównaniu do rdzenia M7. Większa prędkość wnioskowania – 8,7 ms – została osiągnięta kosztem większego zużycia energii – 70mW. Zużyta energia jest oczywiście mniejsza niż dla M7, ponieważ cykl trwa krócej, ale z punktu widzenia zużycia energii układ GAP8 okazał się mniej wydajny w tym punkcie pracy.
Projektujesz elektronikę? Zarezerwuj 4 października 2018 roku na największą w Polsce konferencję dedykowaną projektantom, Evertiq Expo Kraków 2018. Przeszło 50 producentów i dystrybutorów komponentów do Twojej dyspozycji, ciekawe wykłady i świetna, twórcza atmosfera. Jesteś zaproszony, wstęp wolny: kliknij po szczegóły.Wraz ze wzrostem liczby węzłów IoT maleje przepustowość sieci oraz wzrasta opóźnienie w działaniu aplikacji. Ponadto wykorzystanie chmury sprawia, że wdrażanie aplikacji IoT w regionach o ograniczonej lub zawodnej łączności jest trudne a czasami nawet niemożliwe. Jednym z rozwiązań tego problemu jest przetwarzanie danych na krawędzi, wykonywane bezpośrednio w źródle danych, to znaczy w węźle brzegowym sieci IoT. Coraz powszechniejsze staje się wykorzystanie w tym celu splotowych sieci neuronowych CNN (Convolutional Neural Network), które przeprowadzają analizę danych bezpośrednio u źródła, redukując tym samym opóźnienia a także oszczędzając zużycie energii potrzebne do transmisji danych. Firma ARM opublikowała niedawno nową bibliotekę CMSIS-NN stworzoną specjalnie dla takich sieci. CMSIS-NN to zbiór wydajnych jąder (kerneli) sieci neuronowych, opracowanych w celu zwiększenia wydajności i zminimalizowania zużycia pamięci przez sieci neuronowe. W celu oceny wnioskowania CMSIS-NN użyto procesorów ARM Cortex-M przeznaczonych dla inteligentnych urządzeń brzegowych IoT. Przeprowadzone testy na rdzeniu ARM Cortex-M7 wykazały 4,6-krotny wzrost wydajności/przepustowości i 4,9-krotną poprawę efektywności energetycznej w stosunku do podstawowego kernela. Aby zweryfikować te dane, firma GreenWaves Technologies przeprowadziła własne testy porównawcze, wykorzystując, opracowany przez siebie i wprowadzony na rynek na początku 2018 roku, procesor GAP8. Procesor oparty jest na architekturze RISC-V i zoptymalizowany pod kątem przetwarzania obrazu i dźwięku, w tym wnioskowania z użyciem splotowej sieci neuronowej (CNN).© Evertiq
Rysunek 1. Porównanie wielkości procesora GAP8 do jednego eurocenta, © ARM
Nowy układ to wysoce oszczędny w pobór energii System-on-a-Chip, umożliwiający masowe wdrażanie tanich i inteligentnych urządzeń, które przechwytują, analizują, klasyfikują i działają na połączeniu różnych źródeł danych, takich jak obrazy, dźwięki lub wibracje. GAP8 łączy w sobie wszystko, co niezbędne do obsługi czujników: wstępne przetwarzanie, analizę i wydajną pracę na rozbudowanych źródłach danych. Posiada 8 rdzeni oraz akcelerator HWCE (Hardware Convolution Engine). Dzięki temu GAP8 posiada wysoką wydajność energetyczną, która umożliwia działanie urządzeń IoT na akumulatorach przez wiele lat, zapewniając tym samym niskie koszty instalacji i eksploatacji. Nowy procesor kieruje się do produktów przemysłowych i konsumenckich integrujących sztuczną inteligencję i zaawansowane funkcje, takie jak rozpoznawanie obrazu, liczenie ludzi i przedmiotów, monitorowanie stanu maszyn, ochrona domów i mieszkań, rozpoznawanie mowy, robotyka konsumencka, urządzenia do noszenia i inteligentne zabawki.
Rysunek 2. Schemat blokowy mikroprocesora GAP8
Testom porównawczym wydajności obliczeniowej poddano dwa mikrokontrolery GAP8 i STM32 F7 oparty na rdzeniu ARM Cortex-M7. W obu przypadkach wykorzystano ten sam graf sieci neuronowej wyszkolonej w zestawie danych CIFAR-10, składający się z 60 000 kolorowych obrazów 32x32 podzielonych na 10 klas. Firma ARM w swoich testach wykorzystała również mikrokontroler STM32 F7. Układ F7 produkowany jest w technologii 90 nm, która jest szczególnie mało energooszczędna, kiedy wykorzystujemy w testach maksymalną prędkość 217 MHz. Dla uzyskania większej wiarygodności rezultatów w testach poboru mocy wykorzystano układ STM32 H7, który posiada maksymalną częstotliwość taktowania równą 400 MHz. Wykorzystując z tego jedynie 217 MHz zagwarantowano dużo mniejsze zużycie energii i porównywalność wyników. STM32 H7 bazuje na tym samym rdzeniu co ARM M7, co gwarantuje podobny cykl pracy jak w F7. Dodatkowo układ wytwarzany jest w technologii 40 nm, która jest dużo bardziej bliższa technologii 55-nanometrowego procesu TSMC zastosowanego w układzie GAP8.
Tabela 1. Wyniki testów porównawczych wydajności obliczeniowej dla GAP8 i STM32 F7 oraz poboru mocy dla GAP8 i STM32 H7
Analiza testów wydajności
W przypadku układu STM32 F7 prędkość wnioskowania wyniosła 99,1 ms przy wykonanych 21 milionach cykli (wszystkie wagi posiadały 8-bitową kwantyzację sygnału). Natomiast w specyfikacji producent deklaruje wydajność na poziomie 24.7 MOPS. Osiągnięty rezultat może świadczyć o tym, że jest jeszcze miejsce na dalszą optymalizację architektury ARM. GAP8 wymaga jedynie 1,5 miliona cykli do uruchomienia tej samej operacji. Dlaczego GAP8 wykorzystuje tak mało cykli? Po pierwsze, pracuje na 8 rdzeniach, a niezwykle wydajna architektura stworzona do zapewnienia równoległości procesów, umożliwia uzyskanie od 7 do 8-krotnego współczynnika przyspieszenia (speedup). Po drugie, zoptymalizowane instrukcje DSP/SIMD w GAP8 zapewniają wysoką równoległość operacjom splotu. I wreszcie precyzyjna kontrola pamięci generuje prawdziwą korzyść w postaci liczby cykli używanych do ładowania i przechowywania wag oraz danych wejściowych i wyjściowych z węzłów grafów sieci neuronowej. Wszystkie wspomniane czynniki pozwalają osiągnąć ten sam czas wykonania wnioskowania 99,1 ms, jednak dla dużo mniejszej prędkości zegara 15,4 MHz. To z kolei pozwala na uruchamianie rdzeni już przy napięciu 1V i redukcję zużycia energii do poziomu 3,7 mW podczas pracy. Uzyskana w teście wydajność energetyczna układu GAP8 jest 16-krotnie lepsza w stosunku do rdzenia M7 zaimplementowanego w STM32 H7. Jest to więc dobry powód do tego, żeby dla podobnych obciążeń wybrać bardziej energooszczędny układ GAP8.
Dla porównania wykonano test dla maksymalnej prędkości zegara w GAP8 - 175 MHz i napięcia 1,2V. Uzyskano 11-krotny wzrost wydajności obliczeniowej w porównaniu do rdzenia M7. Większa prędkość wnioskowania – 8,7 ms – została osiągnięta kosztem większego zużycia energii – 70mW. Zużyta energia jest oczywiście mniejsza niż dla M7, ponieważ cykl trwa krócej, ale z punktu widzenia zużycia energii układ GAP8 okazał się mniej wydajny w tym punkcie pracy.
W testach nie wykorzystywano dodatkowego akceleratora HWCE. Dzięki temu wykazano jak bardzo efektywny jest GAP8, jako silnik obliczeniowy ogólnego przeznaczenia. Niewątpliwie użycie HWCE zmniejszyłoby dodatkowo zużycie energii od 2 do 3 razy. Wykonane testy pokazały, że wprowadzone innowacje w architekturze procesora GAP8 i zestawie instrukcji mogą przynieść olbrzymie korzyści dla kolejnych aplikacji brzegowych IoT. Obecnie firma pracuje już nad nowszą generacją układów. Nowy chip będzie zawierał szereg ulepszeń, w tym jeszcze lepszą efektywność energetyczną, w wyniku zmiany procesu na FD-SOI 28/22 nm. Są również plany na wprowadzenie zewnętrznego radia RF do kolejnego układu, tak aby umożliwić łączność bezprzewodową. Firma przygotowała również zestaw rozwojowy GAPUINO, który obejmuje płytkę z procesorem GAP8, płytkę z różnymi czujnikami, moduł kamery QVGA i zestaw GAP8 SDK. Na razie GAPUINO dostępne jest w przedsprzedaży. Zamówienia będą realizowane na zasadzie "kto pierwszy, ten lepszy". Wysyłkę do klientów zaplanowano na kwiecień bieżącego roku.Rysunek 3. Zestaw rozwojowy GAPUINO

