


© jim hughes dreamstime.com
Technologie |
Nowe podeście do rozpoznawania mowy
Jak efektywnie odfiltrować hałas – czujnik optyczny dla systemów ASR od VocalZoom
Pierwsze prymitywne maszyny rozpoznające mowę ludzką powstały już w latach pięćdziesiątych XX wieku, jednak do dzisiaj działanie systemów ASR (Automatic Speech Recognition) pozostawia wiele do życzenia. Firma VocalZoom opracowała technologię znacznie poprawiającą trafność rozpoznawania wypowiedzi poprzez wykorzystanie dodatkowego sygnału optycznego.
Systemy komunikacji człowiek-maszyna (HMC – Human to Machine Communication) w różnym stopniu umożliwiają maszynom rozumienie mowy ludzkiej, pozwalając na sterowanie maszyną za pomocą głosu. Taka komunikacja może stać się również sposobem na ochronę dostępu do różnych interfejsów albo kont poprzez uwierzytelnianie na podstawie barwy głosu mówcy.
Kontrola za pomocą głosu w aplikacjach HMC jest krokiem naprzód w stronę coraz bardziej wygodnych i intuicyjnych interfejsów użytkownika, bardzo pożądanych i praktycznych w dzisiejszym, coraz bardziej mobilnym i skomunikowanym świecie. Jednakże obecne systemy rozpoznawania mowy ludzkiej w aplikacjach HMC działają zadowalająco tylko w przypadku, gdy słowa użytkownika wypowiadane są wyraźnie i bez towarzyszących mu dźwięków tła.
Maszyny nie są w stanie domyślić się treści wypowiedzi, gdy nie jest ona dobrze słyszana, tak jak robią to ludzie, gdy dźwięki tła częściowo zagłuszają mówcę. Programy rozpoznające mowę mogą być wytrenowane do rozumienia akcentów i różnych wzorców wypowiedzi, jednak nie są w stanie ignorować zakłóceń pochodzących z tła. Rozwiązania HMC muszą zatem być zdolne do izolowania hałasu, nie będącego częścią interesującej nas wypowiedzi. Zwykłe akustyczne mikrofony nie są przystosowane do tego stopnia ukierunkowania akwizycji danych, zatem problem zakłóceń tła nie może być rozwiązany, nawet jeśli używamy całych zestawów mikrofonów czy matryc wielomikrofonowych.
W systemie VocalZoom wykorzystano i unowocześniono inną technologię wykrywania dźwięku, zaimplementowaną w nowej kategorii sensorów HMC, które wzmacniają sygnał wyjściowy mikrofonów akustycznych poprzez porównanie z dodatkowym sygnałem referencyjnym. Sygnał ten powstaje na podstawie danych optycznych, generowanych podczas mowy przez wibracje, pochodzące od skóry twarzy, z obszarów otaczających usta oraz z warg, policzków, szyi i gardła. Poprzez obserwację tych obszarów, mały sensor VocalZoom, charakteryzujący się także niskim poborem mocy, bada wibracje i przetwarza te dane na sygnał audio, dzięki czemu możliwe jest wyizolowanie głosu mówcy.
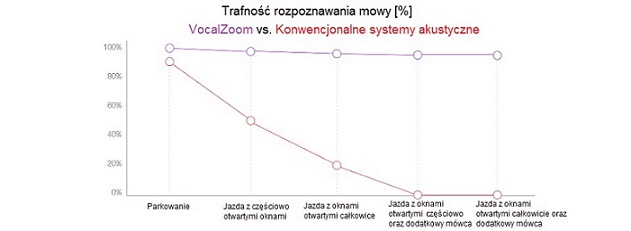
Rysunek: W poruszającym się pojeździe, gdy otwarte są okna i słyszalni są inni mówcy, trafność rozpoznawania mowy w konwencjonalnych systemach akustycznych spada do 0%. Sensor HMC od VocalZoom w takim samym otoczeniu potrafi utrzymać trafność rozpoznawania na poziomie ponad 90%.
 © VocalZoom
Jest to niskokosztowa i energooszczędna implementacja technologii stosowanej w interferometrach. Potrafią one wykrywać drgania z zakresów nanometrycznych nawet z odległości ponad 1 mili, poprzez detekcję różnic fazowych pomiędzy źródłem a odbita falą. Aby obniżyć koszty tej technologii do poziomu przystępnego prywatnym klientom (zwykle interferometry to urządzenia, których cena sięga tysięcy albo nawet milionów dolarów), skrócono dystans detekcji do jednego metra, używając bezpiecznego lasera VCSEL 1 klasy, który jest kierowany na twarz mówcy w celu wykrycia wibracji. Wibracje powodują modulację fazy odbitego promienia, a algorytmy wbudowane w wyspecjalizowany układ ASIC pozwalają na uzyskanie wyjściowego sygnału poprzez interfejs I2S.
Paradoksalnie, jeśli poziom zakłóceń akustycznych tła wzrasta, precyzja rozpoznawania mowy jest większa. Technologia VocalZoom testowana w głośnym otoczeniu pozwala utrzymać trafność rozpoznanych wypowiedzi na poziomie 90-97%. Tak dobrym wynikom sprzyja tzw. efekt Lombarda, polegający na tym, że mówca znajdujący się w hałaśliwym otoczeniu, podświadomie podnosi natężenie głosu, aby być lepiej słyszalnym, co wiąże się również z silniejszymi drganiami skóry jego twarzy. Dzięki temu system osiąga wyższą wartość współczynnika SNR (Signal-to-Noise Ratio), ponieważ głosy tła wciąż nie są wykrywane, wzrasta natomiast sygnał pochodzący z twarzy mówcy. Ta cecha systemu daje ogromne możliwości jego wykorzystania w przypadku komunikacji w służbach ratunkowych, w sytuacjach, gdy syreny, ogień, walące się budynki, czy też podniesione głosy innych ludzi mogą zagłuszyć słowa mówcy.
Ze względu na szczególne i niepowtarzalne cechy głosu każdego człowieka oraz towarzyszące im drgania skóry twarzy, sygnał pochodzący z optycznego sensora jest jednoznacznie kojarzony z mówcą, co skutkuje dużo bardziej precyzyjnym rozpoznawaniem mowy, a także możliwością wykorzystania uzyskanego sygnału w biometrycznych systemach autentyfikacji.
Możliwości, które oferuje system VocalZoom, to coś więcej niż tylko wyższa jakość rozmów telefonicznych, czy dokładniejszy i bardziej trafny system rozpoznawania mowy, pozwalający na wydawanie komend i kontrolowanie maszyny za pomocą słów. Technologia może potencjalnie zostać wykorzystana w wielu innych dziedzinach, np. przy wykrywaniu bliskości obiektów, czy przy pomiarach częstości akcji serca. Technologia czujnika VocalZoom może odegrać kluczową rolę w podniesieniu standardów działania systemów HMC w niezwykle szerokim wachlarzu zastosowań.
© VocalZoom
Jest to niskokosztowa i energooszczędna implementacja technologii stosowanej w interferometrach. Potrafią one wykrywać drgania z zakresów nanometrycznych nawet z odległości ponad 1 mili, poprzez detekcję różnic fazowych pomiędzy źródłem a odbita falą. Aby obniżyć koszty tej technologii do poziomu przystępnego prywatnym klientom (zwykle interferometry to urządzenia, których cena sięga tysięcy albo nawet milionów dolarów), skrócono dystans detekcji do jednego metra, używając bezpiecznego lasera VCSEL 1 klasy, który jest kierowany na twarz mówcy w celu wykrycia wibracji. Wibracje powodują modulację fazy odbitego promienia, a algorytmy wbudowane w wyspecjalizowany układ ASIC pozwalają na uzyskanie wyjściowego sygnału poprzez interfejs I2S.
Paradoksalnie, jeśli poziom zakłóceń akustycznych tła wzrasta, precyzja rozpoznawania mowy jest większa. Technologia VocalZoom testowana w głośnym otoczeniu pozwala utrzymać trafność rozpoznanych wypowiedzi na poziomie 90-97%. Tak dobrym wynikom sprzyja tzw. efekt Lombarda, polegający na tym, że mówca znajdujący się w hałaśliwym otoczeniu, podświadomie podnosi natężenie głosu, aby być lepiej słyszalnym, co wiąże się również z silniejszymi drganiami skóry jego twarzy. Dzięki temu system osiąga wyższą wartość współczynnika SNR (Signal-to-Noise Ratio), ponieważ głosy tła wciąż nie są wykrywane, wzrasta natomiast sygnał pochodzący z twarzy mówcy. Ta cecha systemu daje ogromne możliwości jego wykorzystania w przypadku komunikacji w służbach ratunkowych, w sytuacjach, gdy syreny, ogień, walące się budynki, czy też podniesione głosy innych ludzi mogą zagłuszyć słowa mówcy.
Ze względu na szczególne i niepowtarzalne cechy głosu każdego człowieka oraz towarzyszące im drgania skóry twarzy, sygnał pochodzący z optycznego sensora jest jednoznacznie kojarzony z mówcą, co skutkuje dużo bardziej precyzyjnym rozpoznawaniem mowy, a także możliwością wykorzystania uzyskanego sygnału w biometrycznych systemach autentyfikacji.
Możliwości, które oferuje system VocalZoom, to coś więcej niż tylko wyższa jakość rozmów telefonicznych, czy dokładniejszy i bardziej trafny system rozpoznawania mowy, pozwalający na wydawanie komend i kontrolowanie maszyny za pomocą słów. Technologia może potencjalnie zostać wykorzystana w wielu innych dziedzinach, np. przy wykrywaniu bliskości obiektów, czy przy pomiarach częstości akcji serca. Technologia czujnika VocalZoom może odegrać kluczową rolę w podniesieniu standardów działania systemów HMC w niezwykle szerokim wachlarzu zastosowań.
© VocalZoom
Jest to niskokosztowa i energooszczędna implementacja technologii stosowanej w interferometrach. Potrafią one wykrywać drgania z zakresów nanometrycznych nawet z odległości ponad 1 mili, poprzez detekcję różnic fazowych pomiędzy źródłem a odbita falą. Aby obniżyć koszty tej technologii do poziomu przystępnego prywatnym klientom (zwykle interferometry to urządzenia, których cena sięga tysięcy albo nawet milionów dolarów), skrócono dystans detekcji do jednego metra, używając bezpiecznego lasera VCSEL 1 klasy, który jest kierowany na twarz mówcy w celu wykrycia wibracji. Wibracje powodują modulację fazy odbitego promienia, a algorytmy wbudowane w wyspecjalizowany układ ASIC pozwalają na uzyskanie wyjściowego sygnału poprzez interfejs I2S.
Paradoksalnie, jeśli poziom zakłóceń akustycznych tła wzrasta, precyzja rozpoznawania mowy jest większa. Technologia VocalZoom testowana w głośnym otoczeniu pozwala utrzymać trafność rozpoznanych wypowiedzi na poziomie 90-97%. Tak dobrym wynikom sprzyja tzw. efekt Lombarda, polegający na tym, że mówca znajdujący się w hałaśliwym otoczeniu, podświadomie podnosi natężenie głosu, aby być lepiej słyszalnym, co wiąże się również z silniejszymi drganiami skóry jego twarzy. Dzięki temu system osiąga wyższą wartość współczynnika SNR (Signal-to-Noise Ratio), ponieważ głosy tła wciąż nie są wykrywane, wzrasta natomiast sygnał pochodzący z twarzy mówcy. Ta cecha systemu daje ogromne możliwości jego wykorzystania w przypadku komunikacji w służbach ratunkowych, w sytuacjach, gdy syreny, ogień, walące się budynki, czy też podniesione głosy innych ludzi mogą zagłuszyć słowa mówcy.
Ze względu na szczególne i niepowtarzalne cechy głosu każdego człowieka oraz towarzyszące im drgania skóry twarzy, sygnał pochodzący z optycznego sensora jest jednoznacznie kojarzony z mówcą, co skutkuje dużo bardziej precyzyjnym rozpoznawaniem mowy, a także możliwością wykorzystania uzyskanego sygnału w biometrycznych systemach autentyfikacji.
Możliwości, które oferuje system VocalZoom, to coś więcej niż tylko wyższa jakość rozmów telefonicznych, czy dokładniejszy i bardziej trafny system rozpoznawania mowy, pozwalający na wydawanie komend i kontrolowanie maszyny za pomocą słów. Technologia może potencjalnie zostać wykorzystana w wielu innych dziedzinach, np. przy wykrywaniu bliskości obiektów, czy przy pomiarach częstości akcji serca. Technologia czujnika VocalZoom może odegrać kluczową rolę w podniesieniu standardów działania systemów HMC w niezwykle szerokim wachlarzu zastosowań.